The Leapfrog Hackathon 2025 was an exhilarating, week-long event that brought together 60 brilliant minds from diverse backgrounds, leveraging AWS tools to build AI-powered solutions. It was an incredible opportunity for us to work alongside developers, designers, quality assurance experts, and push our skills to deliver a product that solved real-world problems.
This year, I participated with my team—φolice—to build a project that addresses the complexities of handling Protected Health Information (PHI) in healthcare systems. Our project, φolice, is a multi-functional, AI-powered tool designed to identify, protect, and manage PHI across diverse environments, including code repositories, web pages, and medical data formats. It integrates seamlessly into various development workflows, providing real-time alerts, automated redaction, and customizable plugins, making it a powerful ally for organizations handling sensitive health data.
Having worked on multiple healthcare projects at Leapfrog, our team had firsthand experience with unique challenges in handling PHI. In fast-paced projects, where deployment planning often overlaps with ongoing releases, distinguishing sensitive PHI from dummy data can be a daunting task. This complexity inspired us to build a flexible, scalable solution that addresses this critical need.
But before we could start tackling this issue, we had to submit a proposal outlining our idea to the core Hackathon team. Once our concept was accepted, the next step was to build a strong, well-rounded team with both an understanding of the problem and the ability to perform under intense time constraints. We brought together six team members, a mix of developers, a quality assurance engineer, and an AWS-certified engineer. With this strong foundation, we set out to design and build a solution that would redefine how PHI is managed in modern healthcare systems.
The team

- Neeraj Lekhak - Lead Engineer, Development
- Ramesh Pokhrel - Lead Engineer, Development
- Pukar Giri - Senior Software Engineer, Development
- Sonu Ranabhat - Senior Software Engineer, QA
- Panas Tiwari - Software Engineer, Development
- Suraj Khayamali - Software Engineer, Development
The plan
To build a system that effectively protects PHI, our first task was to ask ourselves, “Where can PHI be found?”
As developers, our initial instinct was to focus on the code itself. However, we quickly realized that PHI doesn’t just live in code, but it can reside in different places - source codes, log files, documents, and even webpages. It became clear that a flexible, customizable approach that could be tailored to the unique needs of different teams and systems was essential to tackle the challenge of identifying PHI sources.
This led us to design a flexible architecture with a central component, core, responsible for detecting PHI, and a suite of 'Plugins' that add specific capabilities based on the diverse ways teams might encounter sensitive information. Our solution was inspired by tools like Grammarly, which identify writing mistakes in real-time and provide feedback as you type.
We initially envisioned using the ‘Language Server Protocol (LSP)' plugin to identify PHI that might be hidden within the code. But as we kept brainstorming, we came up with additional tools to identify PHI.
Command-Line Interface (CLI) tool: To scan code before it’s committed to a repository, preventing the accidental exposure of sensitive data. Browser extension: To find, hide, highlight, or replace the PHI visible on a web page.
With this modular approach, φolice can be adapted to various scenarios, ensuring comprehensive PHI protection across different workflows and environments.
The name
With a clear plan for what we wanted to build, the next challenge was choosing the right name—a task that is often difficult for developers. We started with 'Sensitive Data Identifier, which described what the tool did, but wasn't very catchy.
As we focused on “PHI” the name evolved into 'PHI Identifier, ’ then 'PHI Police,' and finally, we landed on φolice.
The name φolice (pronounced as Phi Police) uses the Greek letter 'φ' (phi), which represents the sensitive data we aim to protect, with the concept of policing sensitive information. The name was unique and sparked curiosity, often making people ask about its meaning and how it is pronounced, allowing us to explain our project.
Looking back, we’re glad we chose a name that stands out. It captures our mission perfectly—acting as a vigilant protector of sensitive health data across a range of digital environments.
The proposal
This year's hackathon was divided into two stages. The first stage was the proposal. Our team had to create a two-page document explaining the problem we wanted to solve and our proposed solution. We needed to mention system design (architecture), how we would use AI and AWS, privacy concerns, and other important details. Each team was assigned an Advisor, and we were lucky to have Seward Pulitzer as our advisor.
We shared our idea with him, and while he liked it, he also raised an important question on why someone would trust sending their data, especially PHI, to an external server. This was a valid point. This made us realize that our solution must be such that customers can host themselves in their cloud or even run locally as a Small Language Model (SLM).
The architecture
The infrastructure
Our system architecture consisted of a central processing engine, the core, which leveraged artificial intelligence models to identify segments of data potentially containing PHI. In addition, there were multiple plugins that would interact with the core to serve their specific use cases.
To address concerns regarding the transmission of sensitive data for analysis, we designed a separation between the model training and inference phases. The core AI model would undergo training using AWS Sagemaker. Following the training process, the resulting model and its dependencies would be containerized.
This containerized application of the trained core could then be deployed by our users within their own secure AWS Virtual Private Cloud (VPC) environment, utilizing Sagemaker's Bring Your Own Container (BYOC) capability. This deployment model ensured that the actual PHI identification process occurred within the client's isolated cloud infrastructure. Consequently, the data that had to be analyzed remained within their control and did not need to be transmitted to a third-party server.
The only external communication that the client's VPC would have to make would be for authentication purposes, to validate the legitimacy of their subscription through an API gateway. Therefore, the processing of sensitive information would strictly be confined to the customer's own AWS environment.

Architecture Diagram
The AI
The φcore leveraged powerful AI techniques like Natural Language Processing (NLP) to detect PHI. This component relies on sophisticated techniques, specifically Named Entity Recognition (NER), which involves training models to locate and classify specific pieces of information (entities) within text. During the hackathon, we used AWS Comprehend Medical via SageMaker to kickstart this capability. Comprehend Medical, as a HIPAA-eligible service, offered a robust foundation with its pre-trained NER models, making it an excellent choice given our tight timeline and the complexity of medical text.
However, as we envision the future of φcore, our roadmap includes building a fully customized NER model within SageMaker. This will allow us to fine-tune the model for the unique demands of our plugins and the diverse types of data they will encounter, providing even more precise and context-aware PHI detection.
The application
At the heart of our application was φcore, our custom solution for PHI detection, which we built using AWS SageMaker. To power its Natural Language Processing (NLP) capabilities, we designed a system within SageMaker and integrated it with AWS Comprehend Medical. This AWS service provides sophisticated, pre-trained models adept at identifying medical entities, including various types of PHI, from text.
Building this involved several steps within the SageMaker environment:
Endpoint Configuration: We set up SageMaker endpoints to establish a reliable communication channel with the Comprehend Medical service. Data Processing Pipeline: We developed a pipeline to prepare incoming text data for analysis. This included any necessary pre-processing before sending it to Comprehend Medical and post-processing of the results. API Interaction & Logic: Our φcore logic handled the API calls to Comprehend Medical and interpreted its JSON output to accurately identify and extract the potential PHI segments along with their confidence scores.
This SageMaker-based architecture allowed us to rapidly deploy a robust and intelligent PHI detection engine. This engine formed the intelligent core that our various plugins then interacted with. Surrounding this core were the different plugins, each designed to address specific use case
Browser extension: This plugin analyzed all text content within a web page. If PHI was detected, the user was given options to mask, highlight, or replace the sensitive information directly within the web application. This functionality would be invaluable when sharing screens or recording demos of applications containing sensitive data.
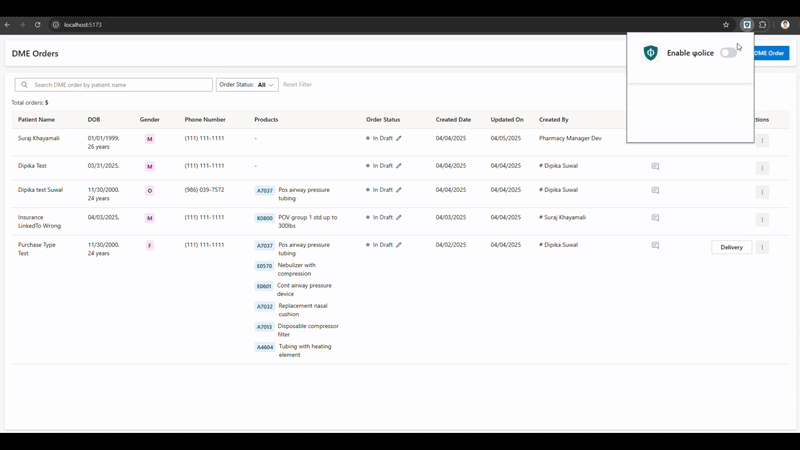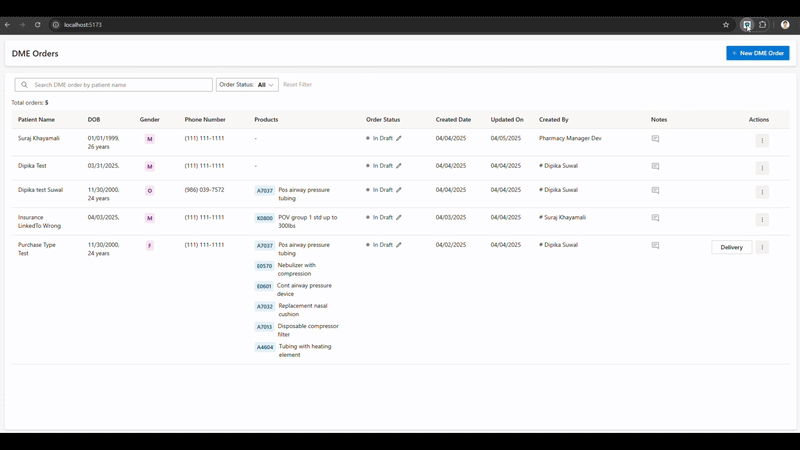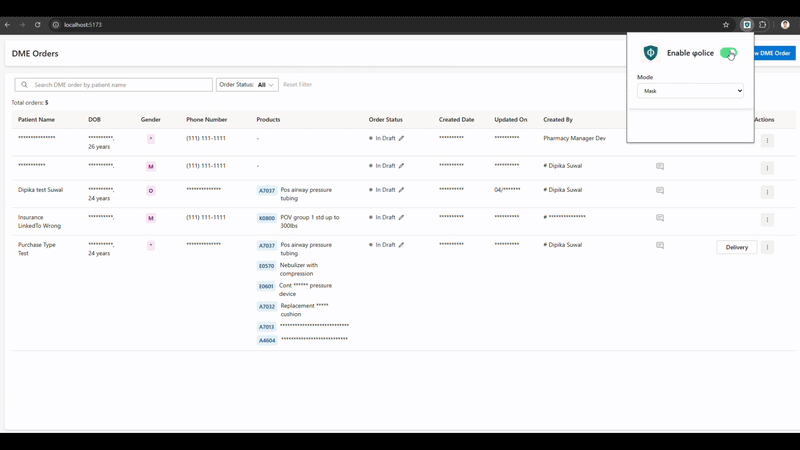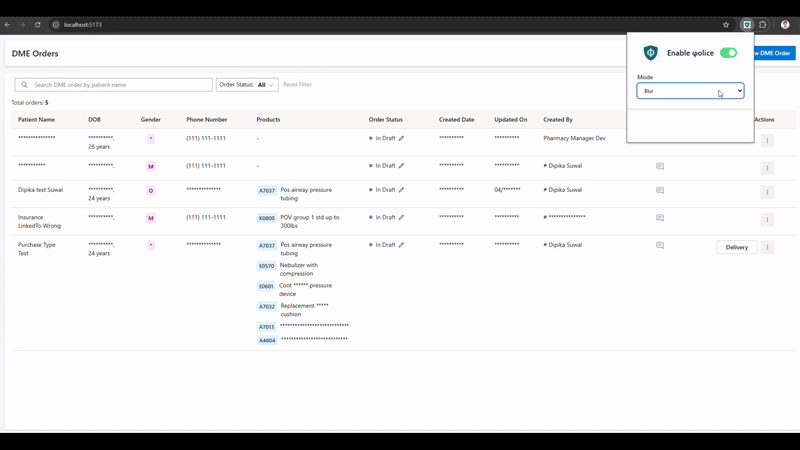
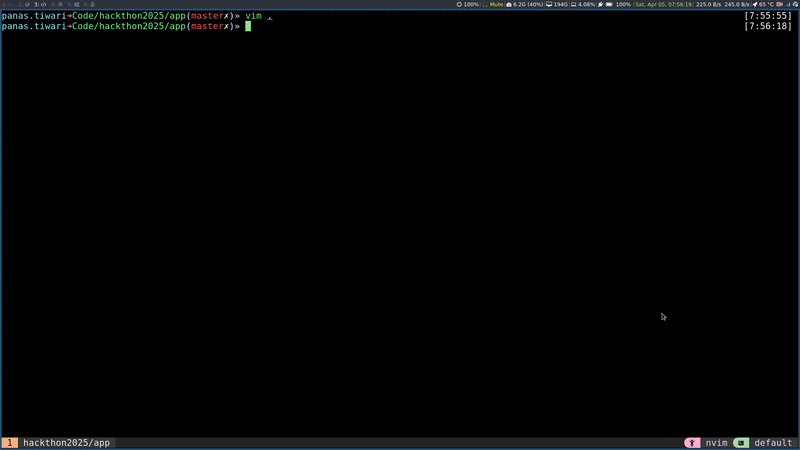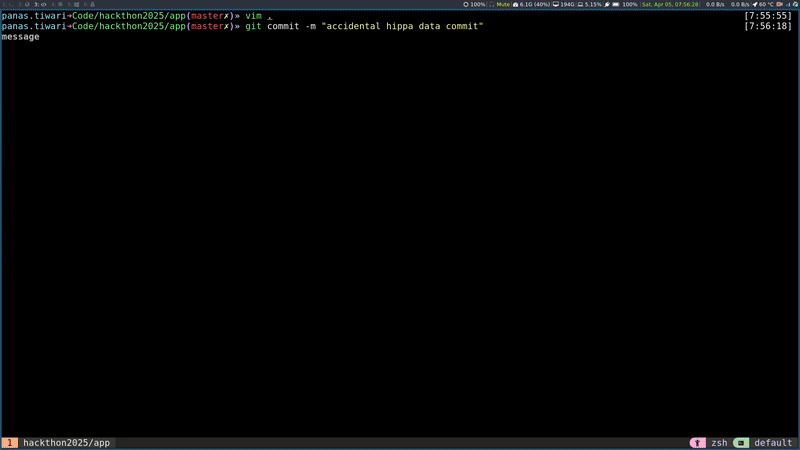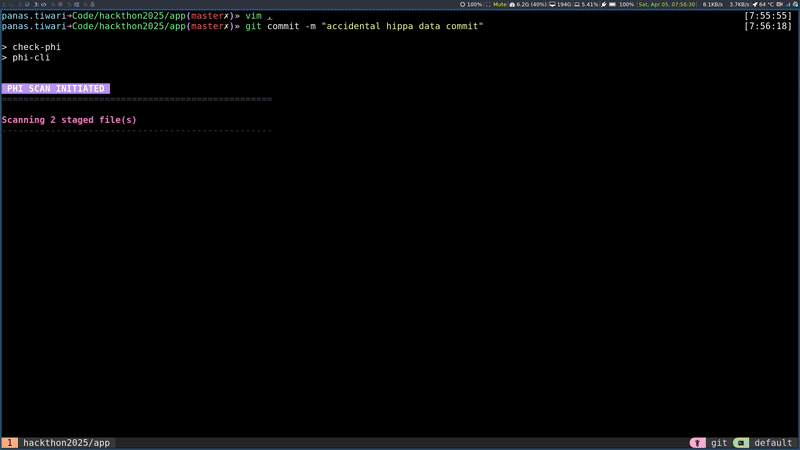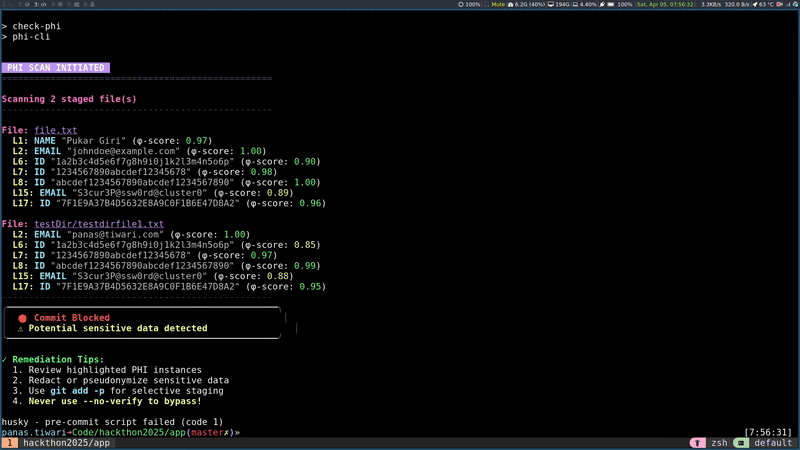
Git pre-commit hook: A Git pre-commit hook is an automated script that Git runs before a commit is finalized. It allows developers to do quality checks and halts the commit if it detects any issue preventing leakage of sensitive information. This plugin utilized a Command Line Interface (CLI) tool, developed using Node.js, to scan staged files for PHI. If any PHI was identified, the tool listed all potential instances, similar to how ESlint reports JavaScript errors, thereby preventing the accidental commit of sensitive information to Git.
LSP server for NeoVim: Another plugin we provided was an LSP server for NeoVim. The Language Server Protocol (LSP) defines a standard way for code editors to communicate with a separate 'Language Server' that provides intelligent features like real-time code analysis and error detection. This NeoVim extension offers real-time identification of PHI within code. It functioned analogously to how a typical Language Server Protocol (LSP) server detects syntax errors.
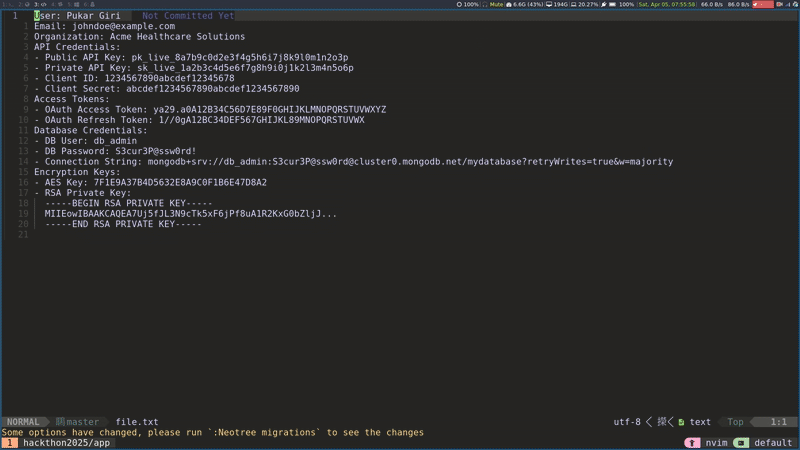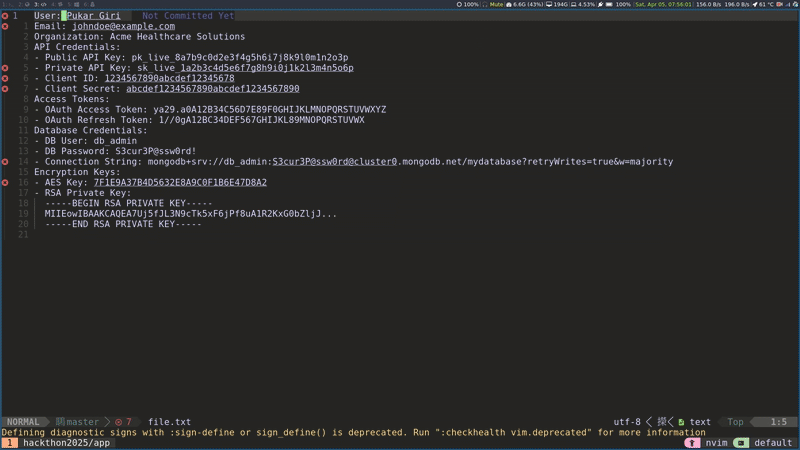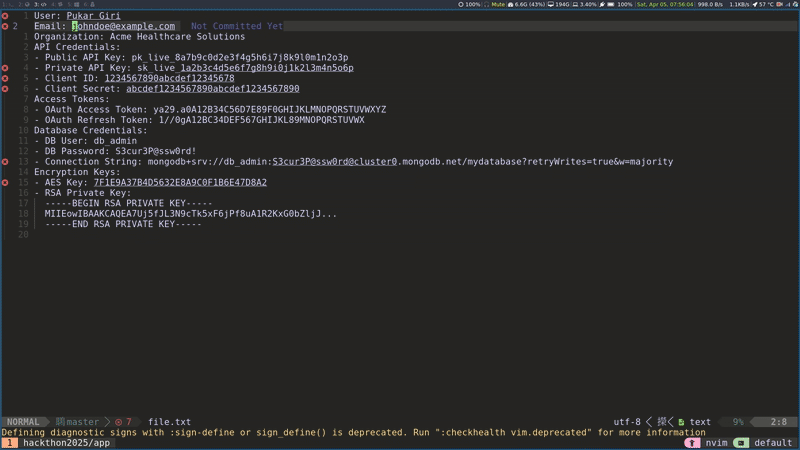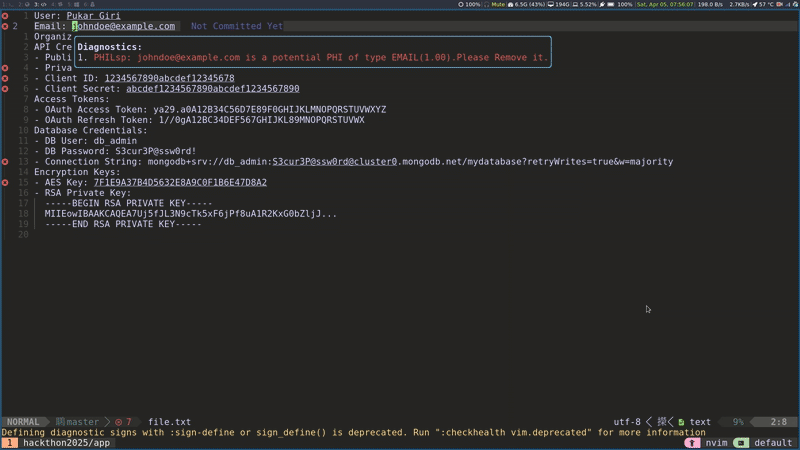
De-identifier: The de-identifier plugin addressed a common requirement in healthcare, which is the need to remove PHI from EDI (Electronic Data Interchange) formats before sharing them with development teams. Leveraging φcore, this plugin identified PHI segments and replaced them with synthetic data.
Furthermore, if our existing plugins did not cater to a specific need, users had the flexibility to develop their own custom plugins that integrate with φcore.

The marathon
After weeks of planning and proposal writing, the day finally came. We had 20 intense hours to build what we had envisioned. Our strategy was to divide and conquer. With so many pieces to develop, utilizing our time as effectively as possible was the only way we could succeed.
The φcore was central to our application, and the plugins depended on it. We understood that if the core weren't ready, it would significantly hinder the progress of plugin development. Therefore, we decided to first build a temporary, simplified version (a mock) that would simulate its behavior using fixed values. For instance, it would replace specific predefined names, dates of birth, addresses, etc., within the text. This allowed the plugin development to proceed in parallel with the ongoing development of the actual φcore.
During plugin development, we adopted an iterative approach with short, achievable milestones to continuously enhance plugins’ capabilities. For the Browser Extension, our initial approach involved sending the entire HTML content to φcore for PHI detection. Once this core functionality was established, we optimized performance by implementing a Depth-First Search (DFS) algorithm to selectively target and send only text nodes to φcore. The browser extension offered several features: masking PHI data, replacing it with synthetic data, and highlighting it. While masking was relatively straightforward, replacing PHI with the fake data was challenging due to potential variations in text length between the original and substituted data.
By systematically addressing these issues, we were able to successfully integrate all the features by 2:00 AM. By this point, the actual φcore and supporting plugins were ready. Our presentation slide was also ready by that time, and we shifted our focus to polishing the application, resolving any remaining bugs, and refining the user interface.
At this critical juncture, some team members were staying awake with caffeine and some recharged with short naps.
The last mile
After a much-needed break, the team regrouped with renewed energy. Some of us immediately dived into editing the demo video, others refined the presentation slides, and a few focused on squashing those last-minute, elusive bugs.
We became so absorbed in our respective tasks that we completely missed the announcement for lunch. As the submission deadline approached, the pressure mounted, and just when it seemed like we were on track, our video editing laptop started freezing intermittently, adding to the stress. Despite these unexpected technical setbacks, we managed to render the final edit and submitted the video at the very last moment, without even a final review.
With the video submitted, it was time for the final presentations. We were slated to present second to last, giving us a nerve-wracking wait as we watched other teams showcase their projects. Our hearts raced with a mix of anxiety and anticipation.
Finally, our turn came, and we presented φolice to the judges. Now, all we could do was wait for the results, hoping our hard work and sleepless nights would pay off. Winning moment
All the projects were impressive, and their presentations were top-notch. However, we had faith in our idea, our product, and the hard work we had put in. When the time finally came for the winner announcement, the first award was for ‘AI Innovation.’
When we heard the name "φolice," we couldn’t contain our excitement and jumped up to collect the prize from Himal Karmacharya, President of Leapfrog. All the exhaustion instantly faded away.
We returned to our seats, eager to hear the results of the other awards. Even though we had already won in one category, we were still hoping for more. As the runner-up was announced, one of our team members, half-jokingly, said, "Of course, we’re not winning two categories." Before he could finish, we heard, "The winner is φolice!"
Our excitement skyrocketed, and the celebration began.
Our journey at the Leapfrog Hackathon culminated in a remarkable double victory for φolice, winning both the 'AI Innovation' award and the overall championship. This achievement underscores not only the ingenuity of our solution but also the critical importance of effectively addressing PHI protection. We believe φolice has the potential to offer significant benefits to teams navigating sensitive healthcare data, and this recognition fuels our excitement to explore its future development and real-world impact.